Abstract
Robot sports, characterized by well-defined objectives, explicit rules, and dynamic interactions, present ideal scenarios for demonstrating embodied intelligence. In this paper, we present VolleyBots, a novel robot sports testbed where multiple drones cooperate and compete in the sport of volleyball under physical dynamics. VolleyBots integrates three features within a unified platform: competitive and cooperative gameplay, turn-based interaction structure, and agile 3D maneuvering. These intertwined features yield a complex problem combining motion control and strategic play, with no available expert demonstrations. We provide a comprehensive suite of tasks ranging from single-drone drills to multi-drone cooperative and competitive tasks, accompanied by baseline evaluations of representative reinforcement learning (RL), multi-agent reinforcement learning (MARL) and game-theoretic algorithms. Simulation results show that on-policy RL methods outperform off-policy methods in single-agent tasks, but both approaches struggle in complex tasks that combine motion control and strategic play. We additionally design a hierarchical policy which achieves 69.5% win rate against the strongest baseline in the 3 vs 3 task, demonstrating its potential for tackling the complex interplay between low-level control and high-level strategy. To highlight VolleyBots’ sim-to-real potential, we further demonstrate the zero-shot deployment of a policy trained entirely in simulation on real-world drones.
Overview
- We introduce VolleyBots, a novel robot sports environment centered on drone volleyball, featuring mixed competitive and cooperative game dynamics, turn-based interactions, and agile 3D maneuvering while demanding both motion control and strategic play.
- We release a curriculum of tasks, ranging from single-drone drills to multi-drone cooperative plays and competitive matchups, and baseline evaluations of representative RL, MARL and game-theoretic algorithms, facilitating reproducible research and comparative assessments.
- We design a hierarchical policy that achieves a 69.5% win rate against the strongest baseline in the 3 vs 3 task, offering a promising solution for tackling the complex interplay between low-level control and high-level strategy.
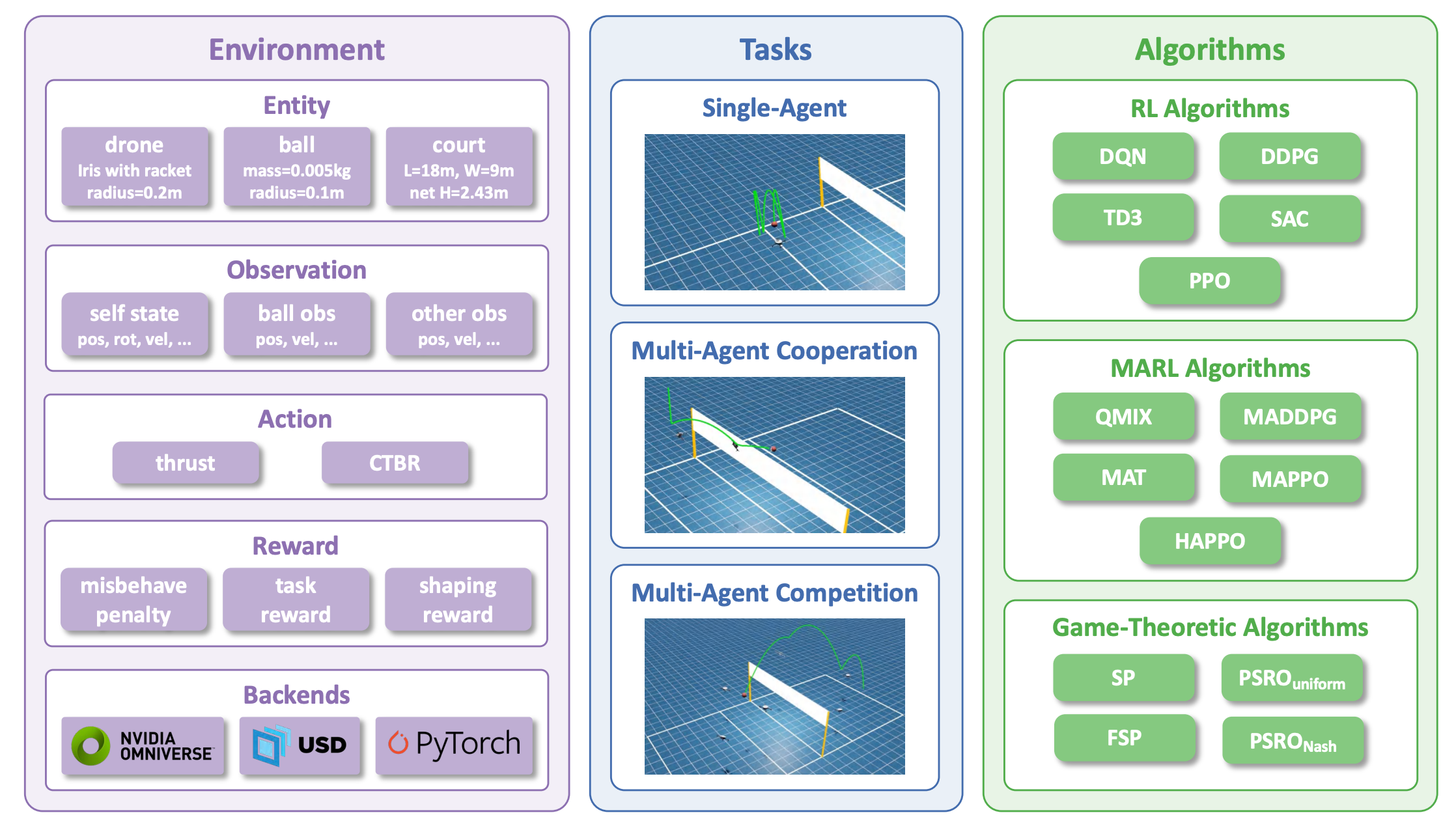
Figure 1. Overview of the VolleyBots Testbed. VolleyBots comprises three components: (1) Environment, supported by Isaac Sim, which defines entities, observations, actions, and reward functions; (2) Tasks, including 3 single-agent tasks, 3 multi-agent cooperative tasks, and 3 multi-agent competitive tasks; and (3) Algorithms, encompassing RL, MARL, and game-theoretic algorithms.
Tasks
Inspired by the way humans progressively learn to play volleyball, we introduce a series of tasks that systematically assess both low-level motion control and high-level strategic play.
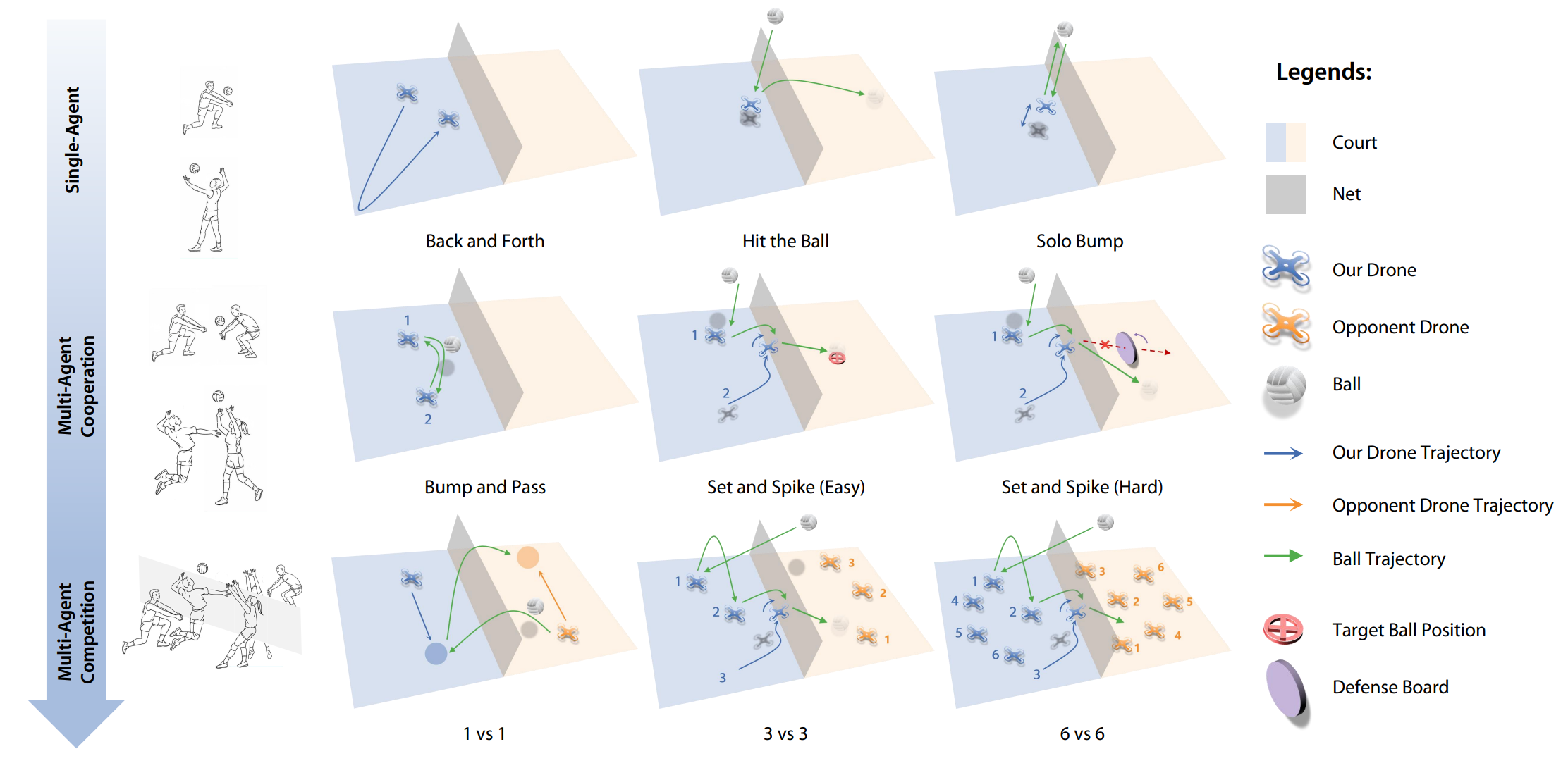
Figure 2. Proposed tasks in the VolleyBots testbed, inspired by the process of human learning in volleyball. Single-agent tasks evaluate low-level control, while multi-agent cooperative and competitive tasks integrate high-level decision-making with low-level control.
Single-Agent Tasks
Single-agent tasks focus on individual drone motion control, requiring a single quadrotor to master fundamental volleyball skills without multi-agent coordination. These tasks serve as building blocks for more complex scenarios.
Back and Forth
The drone sprints between two designated points to complete as many round trips as possible within the time limit.
Hit the Ball
The ball is initialized directly above the drone, and the drone hits the ball once to make it land as far as possible.
Solo Bump
The ball is initialized directly above the drone, and the drone bumps the ball in place to a specific height as many times as possible within the time limit.
Multi-Agent Cooperative Tasks
Cooperative tasks require multiple drones to coordinate in order to achieve a shared objective, combining individual motion skills with team-level communication and role assignment.
Bump and Pass
Two drones work together to bump and pass the ball to each other back and forth as many times as possible within the time limit.
Set and Spike (Easy)
Two drones take on the role of a setter and an attacker. The setter passes the ball to the attacker, and the attacker then spikes the ball downward to the target region on the opposing side.
Set and Spike (Hard)
Similar to Set and Spike (Easy) task, two drones act as a setter and an attacker to set and spike the ball to the opposing side. The difference is that there is a rule-based defense board on the opposing side to intercept the attacker's spike.
Multi-Agent Competitive Tasks
Competitive tasks pit two opposing teams against each other under standard volleyball rules, combining all individual skills and cooperative strategies in an adversarial setting. These tasks represent the core benchmark of VolleyBots.
1 vs 1
One drone on each side competes against the other in a volleyball match and wins by hitting the ball in the opponent's court. When the ball is on its side, the drone is allowed only one hit to return the ball to the opponent's court.
3 vs 3
Three drones on each side form a team to compete against the other team in a volleyball match. The drones in the same team cooperate to serve, pass, spike, and defend within the standard rule of three hits per side.
6 vs 6
Six drones per side form teams on a full-size court under the standard three-hits-per-side rule of real-world volleyball.
Experiments
We evaluate a comprehensive set of baselines across all three task categories. For single-agent tasks, we compare on-policy and off-policy RL algorithms. For cooperative tasks, we evaluate MARL methods. For competitive tasks, we apply game-theoretic approaches including Self-Play (SP), Fictitious Self-Play (FSP), and Policy-Space Response Oracles (PSRO) variants.
Single-Agent Results
For each algorithm, the same set of hyperparameters is used across all tasks to assess its cross-task robustness, while different algorithms are independently tuned for fairness. On-policy RL methods consistently outperform off-policy approaches on single-agent tasks. We also compare their performance under different action spaces. The final results indicate that PRT slightly outperforms CTBR in most tasks. The averaged results over 5 seeds are shown in Table 1.
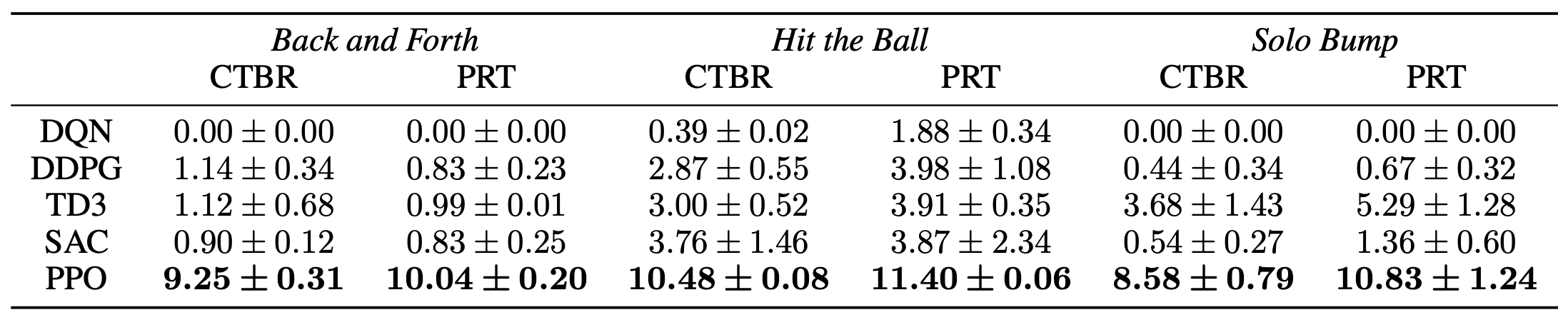
Table 1. Benchmark result of single-agent tasks with different action spaces, including Collective Thrust and Body Rates (CTBR) and Per-Rotor Thrust (PRT). Back and Forth is evaluated by the number of round trips, Hit the Ball is evaluated by the hitting distance, and Solo Bump is evaluated by the number of bumps achieving a certain height.
Multi-Agent Cooperative Results
Comparing the MARL algorithms, on-policy methods also outperform off-policy approaches. We use MAPPO as the default algorithm in subsequent experiments for its consistently strong performance and efficiency. As for different reward functions, it is clear that using reward shaping leads to better performance, especially in more complex tasks like Set and Spike (Hard). The averaged results over 5 seeds are shown in Table 2.
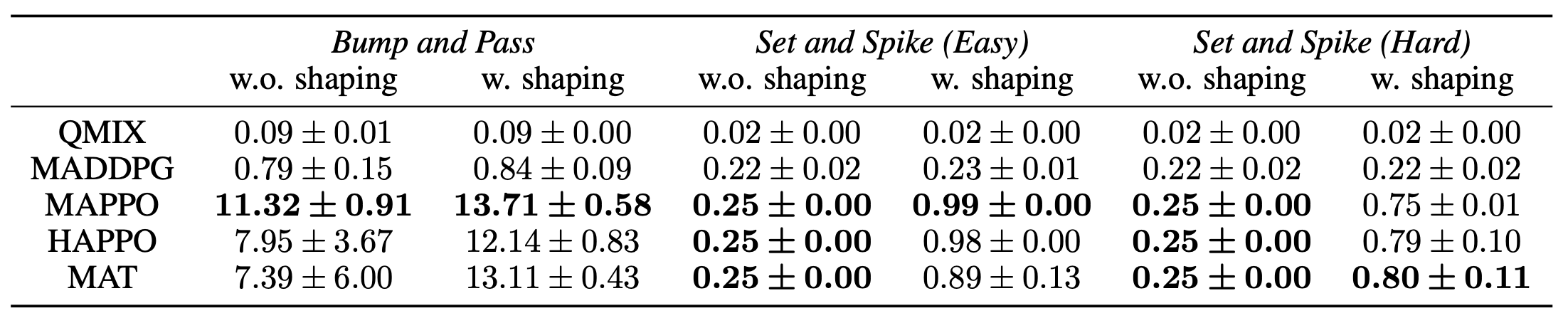
Table 2. Benchmark result of multi-agent cooperative tasks with different reward settings including without and with shaping reward. Bump and Pass is evaluated by the number of bumps, Set the Spike (Easy) and Set the Spike (Hard) are evaluated by the success rate.
Multi-Agent Competitive Results
We evaluate four game-theoretic algorithms including Self-play (SP), Fictitious Self-Play (FSP), Policy-Space Response Oracles (PSRO) with a uniform meta-solver (PSROUniform), and a Nash meta-solver (PSRONash) in multi-agent competitive tasks. We evaluate their performance using approximate exploitability, the average win rate against other learned policies, and Elo rating. In the most difficult 6 vs 6 task, none of the methods converges to an effective strategy. Therefore, we focus our benchmark results on the 1 vs 1 and 3 vs 3 settings.
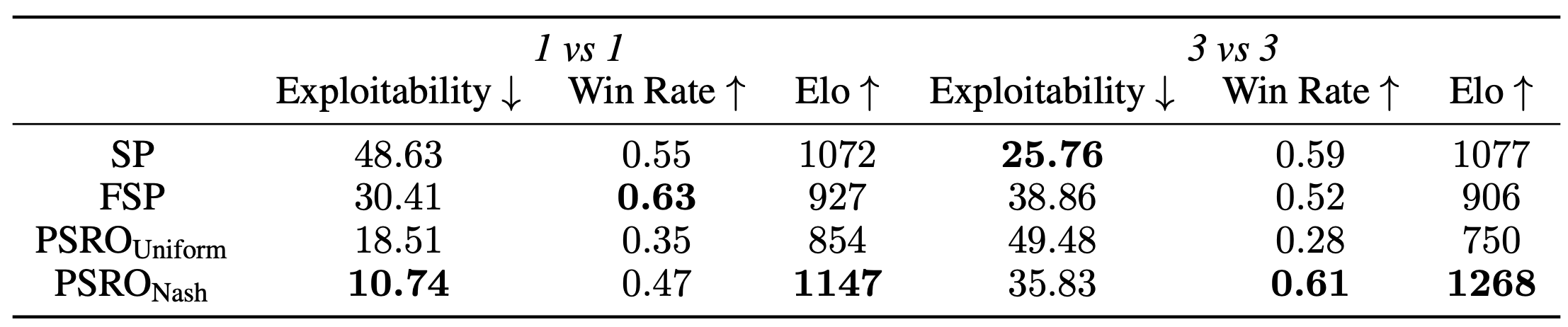
Table 3. Benchmark result of multi-agent competitive tasks including 1 vs 1 and 3 vs 3 with different evaluation metrics.
Hierarchical Policy
To tackle the complex interplay between low-level motion control and high-level strategy in the 3 vs 3 task, we design a hierarchical policy consisting of two levels. At the low level, five primitive drills — Hover, Serve, Pass, Set, and Attack — are individually trained with PPO, each focused on a specific motion skill. At the high level, a rule-based strategy selects which drill to activate based on the current game state, such as the ball's position and the team's hit count. This decoupled design allows each component to be optimized independently. As shown below, the hierarchical policy achieves a 69.5% win rate against the strongest baseline (SP) over 1,000 evaluation episodes, demonstrating its effectiveness in combining motion control and strategic decision-making.
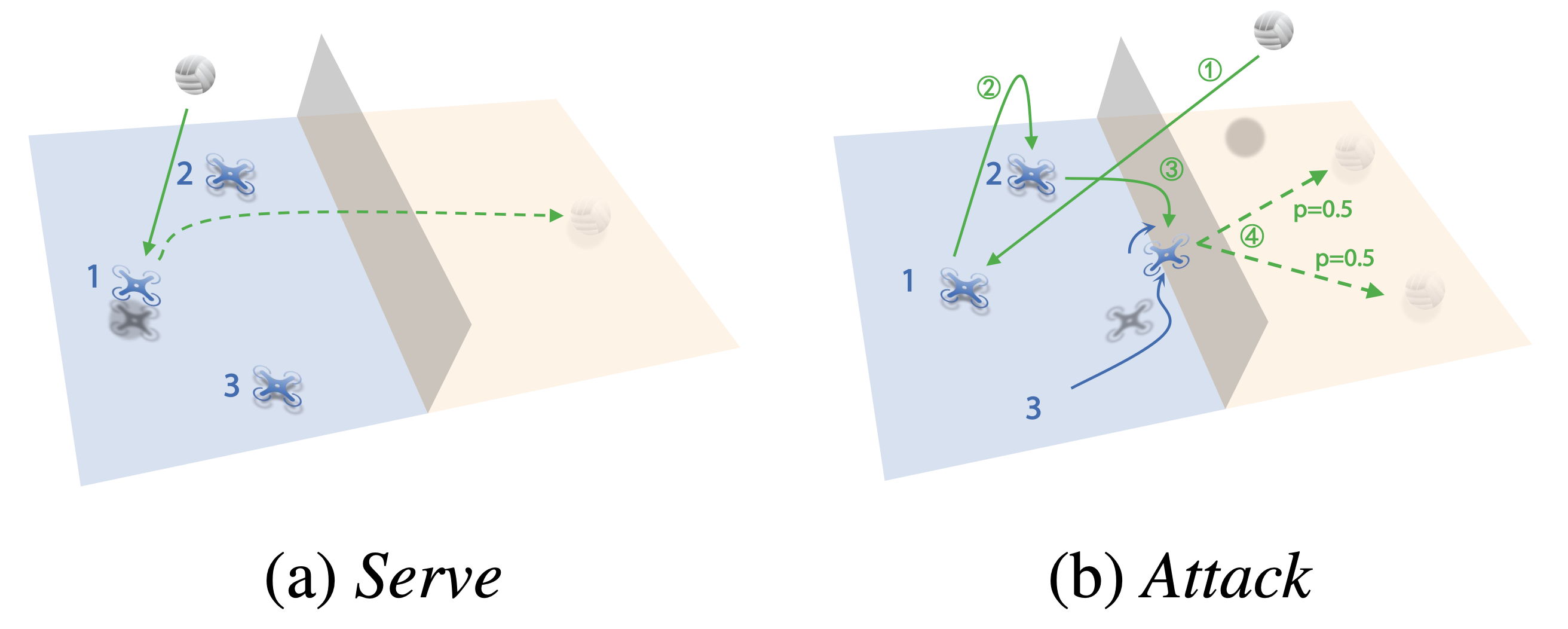
Figure 3. Demonstration of the hierarchical policy selecting Serve and Attack drills in the 3 vs 3 task.
Videos
The following videos showcase learned behaviors across all task categories, including single-agent skill demonstrations, multi-agent cooperative tasks, multi-agent competitive tasks, the hierarchical policy in the 3 vs 3 task, and real-world deployment of the Solo Bump task.
Single-Agent Tasks
Back and Forth
Hit the Ball
Solo Bump
Multi-Agent Cooperative Tasks
Bump and Pass
Set and Spike (Easy)
Set and Spike (Hard)
Multi-Agent Competitive Tasks
1 vs 1
3 vs 3
6 vs 6
Hierarchical Policy
3 vs 3: Serve
3 vs 3: Rally
Real-World Deployment
Real-World Deployment: Solo Bump
BibTeX
If you find our work useful, please cite our paper:
@inproceedings{xu2025volleybots,
title={VolleyBots: A Testbed for Multi-Drone Volleyball Game Combining Motion Control and Strategic Play},
author={Xu, Zelai and Zhang, Ruize and Yu, Chao and Yuan, Huining and Yi, Xiangmin
and Ji, Shilong and Wang, Chuqi and Tang, Wenhao and Gao, Feng
and Ding, Wenbo and Chen, Xinlei and Wang, Yu},
booktitle={Proceedings of the Neural Information Processing Systems (NeurIPS)
Datasets and Benchmarks Track},
year={2025}
}